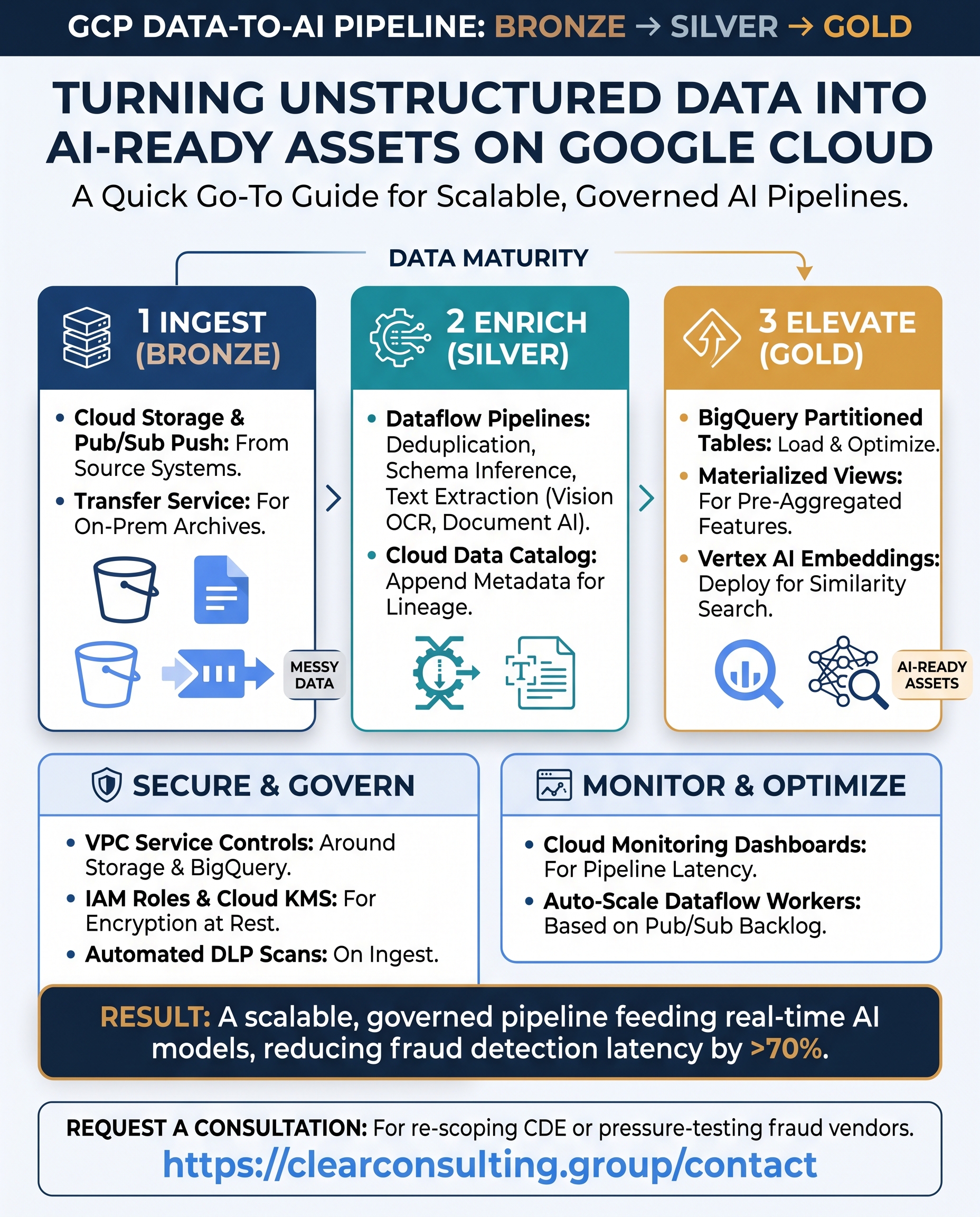
Most data pipelines are built around structured sources — relational tables, CSVs, well-defined schemas. But the data that actually contains business value — contracts, clinical notes, support tickets, emails, scanned forms, call transcripts — is unstructured. Getting that data into a queryable, trustworthy state requires more than an ETL job. It requires a tiered architecture that separates raw storage from cleaned data from enriched, query-ready output.
The medallion architecture (Bronze → Silver → Gold) is the right mental model. This post walks through how to implement it on GCP for unstructured data sources, using Cloud Storage, Pub/Sub, Dataflow, Document AI, Vertex AI, and BigQuery.
The Architecture at a Glance
Source Systems
│
▼
[Pub/Sub Topic] ←─ GCS upload events / external push
│
▼
[Dataflow – Ingestion Job]
│
▼
[GCS – Bronze Bucket] raw, immutable, versioned
│
▼
[Dataflow – Normalization Job]
│
▼
[GCS – Silver Bucket] parsed, deduplicated, schema-tagged
│
▼
[Dataflow – Enrichment Job]
│
▼
[BigQuery – Gold Dataset] structured, embedded, queryableEach tier has a clear contract: Bronze preserves fidelity, Silver enforces structure, Gold enables analytics and ML.
Bronze: Raw Ingestion
The Bronze layer’s only job is to land data quickly and preserve it exactly as it arrived. No transformations, no parsing. Treat it like a write-once archive.
Ingestion via Pub/Sub + Dataflow
For streaming sources (file uploads, API webhooks, email ingest), Pub/Sub is the entry point:
from google.cloud import pubsub_v1
import json
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path("my-project", "raw-document-events")
message = {
"source_uri": "gs://intake-bucket/uploads/contract_2024_0512.pdf",
"source_system": "docusign",
"received_at": "2024-05-12T14:32:00Z",
"content_type": "application/pdf"
}
publisher.publish(topic_path, json.dumps(message).encode("utf-8"))A Dataflow streaming job subscribes to this topic, copies the raw file to the Bronze bucket, and writes a manifest record:
import apache_beam as beam
from google.cloud import storage
import json, hashlib, datetime
class CopyToBronze(beam.DoFn):
def __init__(self, bronze_bucket):
self.bronze_bucket = bronze_bucket
def process(self, element):
msg = json.loads(element)
client = storage.Client()
src_uri = msg["source_uri"]
bucket_name, blob_path = src_uri.replace("gs://", "").split("/", 1)
src_blob = client.bucket(bucket_name).blob(blob_path)
raw_bytes = src_blob.download_as_bytes()
sha = hashlib.sha256(raw_bytes).hexdigest()
date = datetime.date.today().isoformat()
filename = blob_path.split("/")[-1]
dest_path = f"{msg['source_system']}/{date}/{sha[:8]}-{filename}"
dest_blob = client.bucket(self.bronze_bucket).blob(dest_path)
dest_blob.upload_from_string(raw_bytes, content_type=msg["content_type"])
yield {
"bronze_uri": f"gs://{self.bronze_bucket}/{dest_path}",
"source_uri": src_uri,
"sha256": sha,
"content_type": msg["content_type"],
"source_system": msg["source_system"],
"ingested_at": datetime.datetime.utcnow().isoformat()
}Bronze Bucket Configuration
gcloud storage buckets create gs://ccg-bronze-data \
--location=us-central1 \
--uniform-bucket-level-access \
--retention-period=2555d
# Enable versioning — never overwrite Bronze
gcloud storage buckets update gs://ccg-bronze-data --versioningFor regulated industries: attach a CMEK key, enable VPC Service Controls, and lock IAM to a dedicated ingestion service account with storage.objectCreator only — no delete, no overwrite.
Silver: Normalization and Extraction
Silver takes the raw artifacts from Bronze and makes them structurally consistent: text extracted, metadata normalized, duplicates removed, and content-type-specific parsing applied.
Text Extraction by Content Type
Unstructured data arrives in many formats. Your Silver job needs to dispatch on content type:
from google.cloud import documentai_v1 as documentai
from google.cloud import vision
import fitz # PyMuPDF
def extract_text(bronze_uri: str, content_type: str, project_id: str) -> dict:
if content_type == "application/pdf":
return extract_pdf(bronze_uri)
elif content_type in ("image/png", "image/jpeg", "image/tiff"):
return extract_image_ocr(bronze_uri, project_id)
elif content_type == "text/plain":
return extract_plaintext(bronze_uri)
elif content_type in ("message/rfc822", "application/vnd.ms-outlook"):
return extract_email(bronze_uri)
else:
return {"text": None, "extraction_method": "unsupported", "error": f"No extractor for {content_type}"}
def extract_pdf(uri: str) -> dict:
bucket, path = uri.replace("gs://", "").split("/", 1)
raw = storage.Client().bucket(bucket).blob(path).download_as_bytes()
doc = fitz.open(stream=raw, filetype="pdf")
pages = []
for i, page in enumerate(doc):
text = page.get_text("text")
pages.append({"page": i + 1, "text": text, "char_count": len(text)})
full_text = "\n\n".join(p["text"] for p in pages)
# Scanned PDFs produce very little selectable text — fall back to Document AI
if len(full_text.strip()) < 100:
return extract_with_document_ai(uri)
return {"text": full_text, "pages": pages, "extraction_method": "pymupdf"}
def extract_image_ocr(uri: str, project_id: str) -> dict:
client = vision.ImageAnnotatorClient()
image = vision.Image(source=vision.ImageSource(gcs_image_uri=uri))
response = client.document_text_detection(image=image)
return {
"text": response.full_text_annotation.text,
"extraction_method": "vision_api",
"confidence": response.full_text_annotation.pages[0].confidence if response.full_text_annotation.pages else None
}Deduplication
Use the SHA-256 computed at Bronze time. Before writing to Silver, check BigQuery for an existing record:
from google.cloud import bigquery
def is_duplicate(sha256: str, bq_client: bigquery.Client, project: str, dataset: str) -> bool:
query = f"""
SELECT 1
FROM `{project}.{dataset}.silver_manifest`
WHERE sha256 = @sha256
LIMIT 1
"""
job_config = bigquery.QueryJobConfig(
query_parameters=[bigquery.ScalarQueryParameter("sha256", "STRING", sha256)]
)
results = bq_client.query(query, job_config=job_config).result()
return any(True for _ in results)Silver Output Schema
Write Silver output as JSON-lines to GCS (partitioned by date and source system):
{
"silver_uri": "gs://ccg-silver-data/docusign/2024-05-12/abc12345.json",
"bronze_uri": "gs://ccg-bronze-data/docusign/2024-05-12/abc12345-contract.pdf",
"sha256": "a3f9...",
"source_system": "docusign",
"content_type": "application/pdf",
"extraction_method": "pymupdf",
"page_count": 12,
"word_count": 4821,
"extracted_text": "This Agreement is entered into as of...",
"extracted_at": "2024-05-12T15:01:22Z",
"language": "en",
"metadata": {
"author": "Jane Smith",
"created_date": "2024-05-10",
"subject": "Master Services Agreement"
}
}Gold: Enrichment and Analytics-Ready Output
Gold is where the data becomes useful for analytics, search, and ML. This tier adds semantic understanding: entity extraction, classification, embeddings, and structured fields that downstream applications can query directly in BigQuery.
Entity Extraction with Vertex AI
from vertexai.language_models import TextEmbeddingModel, TextGenerationModel
import vertexai, datetime, json, re
vertexai.init(project="my-project", location="us-central1")
def enrich_document(silver_record: dict) -> dict:
text = silver_record["extracted_text"]
if not text or len(text.strip()) < 50:
return {**silver_record, "enrichment_status": "skipped_insufficient_text"}
embed_model = TextEmbeddingModel.from_pretrained("text-embedding-005")
embedding = embed_model.get_embeddings([text[:8000]])[0].values
gen_model = TextGenerationModel.from_pretrained("gemini-1.5-flash-002")
prompt = f"""Extract the following from this document. Return only valid JSON.
Document text (first 3000 chars):
{text[:3000]}
Extract:
- document_type: one of [contract, invoice, clinical_note, support_ticket, email, report, other]
- key_entities: list of {{name, type}} where type is person/org/date/location/amount
- primary_topic: 1 sentence
- sentiment: positive/neutral/negative
- pii_indicators: list of PII types present (e.g. SSN, DOB, account_number) — do not extract values
JSON:"""
response = gen_model.predict(prompt, max_output_tokens=512, temperature=0)
json_match = re.search(r'\{.*\}', response.text, re.DOTALL)
enrichment = json.loads(json_match.group()) if json_match else {}
return {
**silver_record,
"embedding": embedding,
"document_type": enrichment.get("document_type"),
"key_entities": enrichment.get("key_entities", []),
"primary_topic": enrichment.get("primary_topic"),
"sentiment": enrichment.get("sentiment"),
"pii_indicators": enrichment.get("pii_indicators", []),
"enrichment_status": "complete",
"enriched_at": datetime.datetime.utcnow().isoformat()
}Loading into BigQuery Gold Tables
Use partitioned, clustered tables for cost-efficient querying:
CREATE TABLE IF NOT EXISTS `my-project.gold.documents` (
id STRING NOT NULL,
bronze_uri STRING,
silver_uri STRING,
sha256 STRING,
source_system STRING,
content_type STRING,
document_type STRING,
extraction_method STRING,
page_count INT64,
word_count INT64,
language STRING,
primary_topic STRING,
sentiment STRING,
pii_indicators ARRAY<STRING>,
key_entities ARRAY<STRUCT<name STRING, type STRING>>,
embedding ARRAY<FLOAT64>,
extracted_text STRING,
metadata JSON,
ingested_at TIMESTAMP,
extracted_at TIMESTAMP,
enriched_at TIMESTAMP
)
PARTITION BY DATE(ingested_at)
CLUSTER BY source_system, document_type;The embedding column enables vector search via BigQuery’s VECTOR_SEARCH function — no separate vector database required for most use cases:
SELECT
id,
primary_topic,
document_type,
source_system,
distance
FROM VECTOR_SEARCH(
TABLE `my-project.gold.documents`,
'embedding',
(SELECT embedding FROM `my-project.gold.documents` WHERE id = @reference_doc_id),
top_k => 10,
distance_type => 'COSINE'
);Security Considerations for Regulated Industries
If this pipeline touches PHI, financial data, or PCI-scoped content, apply these controls before going to production:
Storage:
- Separate GCS buckets per tier with distinct IAM bindings — Bronze service account cannot write to Silver or Gold
- Customer-managed encryption keys (CMEK) via Cloud KMS; use separate key rings per tier
- Enable VPC Service Controls to prevent data exfiltration across project boundaries
Compute:
- Run Dataflow jobs in a private subnet with no external IP
- Use Workload Identity for all GCP service-to-service auth — no service account key files
- Enable Dataflow worker logging to Cloud Logging with a 90-day retention sink
Data governance:
- Tag columns containing extracted PII in BigQuery with Data Catalog policy tags before any Gold table is shared
- Use BigQuery row-level access policies if multiple business units share the Gold dataset
- The
pii_indicatorsfield tells you that PII is present — never extract the actual values into Gold; leave them in the Silver extracted text under access control
Audit:
- Enable Data Access audit logs on all three GCS buckets and the BigQuery Gold dataset
- Write a manifest to BigQuery at each tier transition — you need a complete lineage chain from Bronze URI to Gold row ID for any compliance inquiry
Monitoring and Operational Health
Set up Cloud Monitoring alerting for:
- Bronze lag: Pub/Sub subscription oldest unacked message age > 5 minutes
- Silver failure rate: Dataflow job
system_lagorelements_droppedabove threshold - Enrichment errors:
enrichment_status = 'failed'rows in Gold table (query via scheduled query + alerting policy) - Gold load latency: time between
extracted_atandenriched_at> SLA threshold
A simple BigQuery scheduled query that runs every 15 minutes and writes to a monitoring table gives you a cheap operational dashboard without a separate observability stack.
What’s Next
This post covers the core pipeline: landing unstructured data in Bronze, normalizing and extracting text in Silver, and enriching to query-ready Gold in BigQuery. The next natural step is connecting the Gold layer to a retrieval system — whether that’s building a RAG pipeline on top of the embeddings for internal search, wiring the document_type classifier into a workflow router, or setting up Dataplex to enforce data quality contracts across all three tiers.
Clear Consulting Group designs and builds production data pipelines for regulated industries, including healthcare and financial services organizations that need compliant, auditable unstructured data infrastructure on GCP. Get in touch if you’re architecting something similar or need a review of an existing pipeline.